
Introduction
Every time an adviser speaks with a client, a conversation takes place that may carry regulatory weight. When AI transcribes that conversation, the result feeds into meeting notes, suitability records, QA reviews, and compliance monitoring. That makes accuracy important, not just as a general quality measure, but as a factor that affects whether the right conclusions are drawn from what was said.
Accuracy in transcription is not a single number. A transcript can look broadly correct and still contain errors that change meaning, misattribute a statement, or silently omit something that matters. This module explains the main way accuracy is measured, what that measurement does and does not capture, and how to set a practical standard for “good enough” based on how the transcript will actually be used.
What you will learn
• What else to check alongside WER in a regulated environment
• What Word Error Rate (WER) is and how it is calculated
• The three types of transcription errors and why they are not equal
• Why the right accuracy standard depends on the use case
Word Error Rate (WER) is the most widely used measure of transcription accuracy. It works by comparing an AI-generated transcript to a reference transcript, typically one produced by a human, and counting how many changes are needed to make them match.
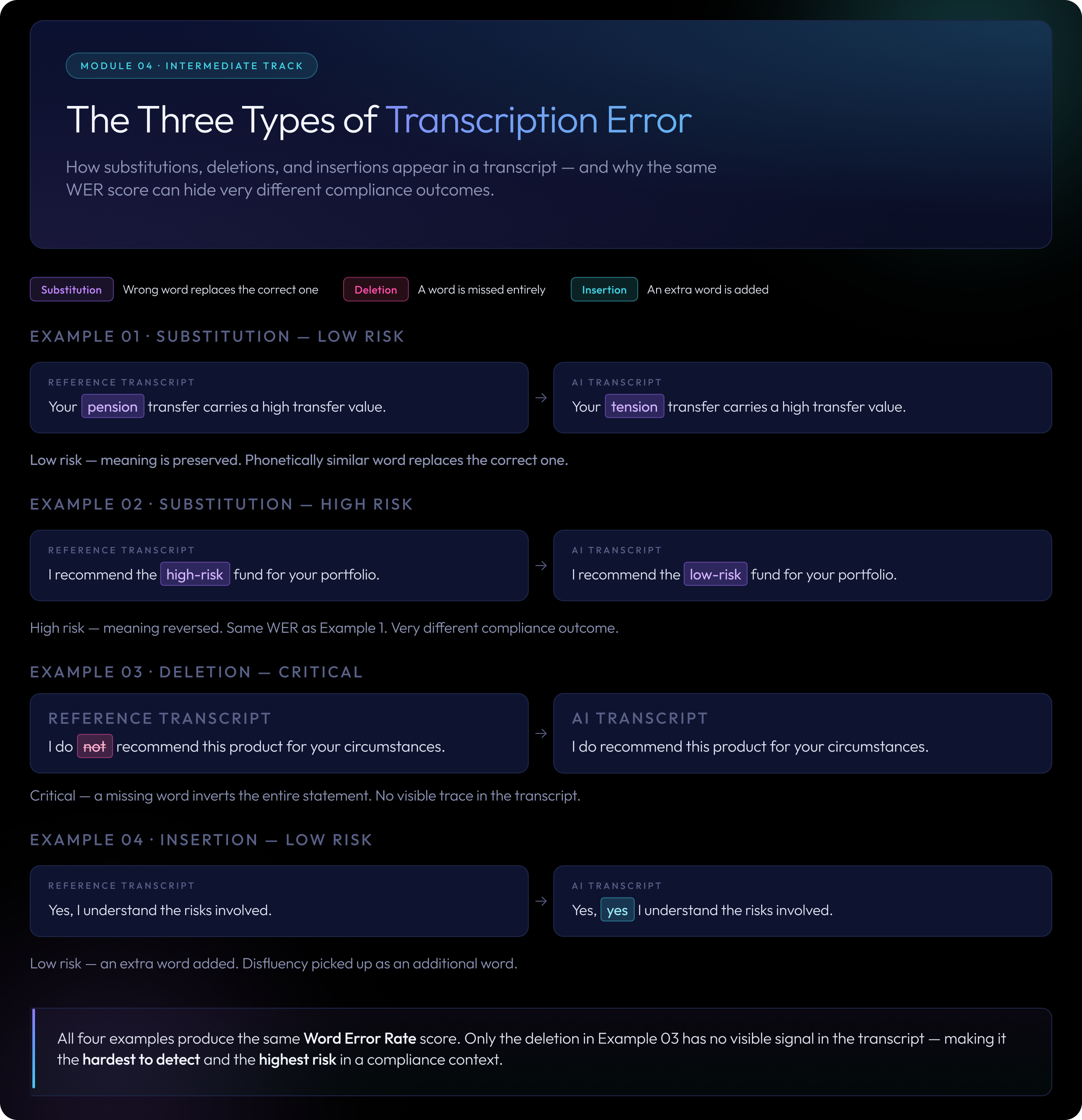
There are three types of transcription error
Those changes fall into three categories:
- Substitution: a word was transcribed incorrectly. “Pension” becomes “tension.” “ISA” becomes “I saw.”
- Deletion: a word was missed entirely. “I do not recommend this” becomes “I recommend this.”
- Insertion: an extra word appears that was never spoken. “Yes, I understand” becomes “Yes, yes I understand.”
WER adds these three types of error together, divides by the total number of words in the reference, and expresses the result as a percentage. A WER of 0% means the transcript is perfect. A WER of 10% means roughly one word in ten was wrong, missing, or added.
The same WER score can hide very different problems
Reference (what was actually said): “Your pension transfer carries a high transfer value.” Transcript (what the AI produced): “Your pension transfer carries a transfer value.”
One word, “high,” was deleted. With a total of eight words in the reference, that gives a WER of 12.5%.
Now consider this version: Transcript: “Your pension transfer carries a low transfer value.”
That is also one error, giving the same WER. But “low” replacing “high” changes the meaning entirely. This is one of WER’s key limitations, which we return to shortly.
WER is calculated after both transcripts are normalised
Before comparing transcripts, both versions are normalised. This means converting to lower case, removing punctuation, and writing numbers out in full. It ensures that “£25,000” and “twenty-five thousand pounds” are treated as equivalent. Different tools handle normalisation differently, which is one reason WER scores from different providers are not always directly comparable.

You will not need to calculate this day to day, but understanding it helps you interpret vendor claims and QA reports accurately.
WER gives you a consistent, repeatable way to compare transcription systems, track how accuracy changes over time, or identify when audio conditions are dragging quality down. If a new recording setup reduces WER from 18% to 11%, that is a meaningful improvement you can measure and report.
But WER has significant limitations in regulated environments.
WER treats every word as equally important, and in financial services, they are not
“Um,” “right,” and “so” carry little weight. “Not,” “unsuitable,” and “high risk” carry a great deal. A transcript with a 6% WER might look strong on paper while silently containing errors in the words that matter most: a missed negation, a wrong product name, a deleted risk warning.
The same WER can produce very different compliance outcomes
WER counts word matches, not meaning. The examples below all share the same WER score, but they represent very different situations in practice:
- “I recommend the balanced fund” becomes “I recommend a balanced fund” → minor, low risk
- “I recommend the high-risk fund” becomes “I recommend the low-risk fund” → substitution, high risk
- “I do not recommend this product” becomes “I recommend this product” → deletion, critical
The third example shows why deletion errors deserve particular attention. A single missing word can completely invert a recorded statement without leaving any visible trace in the transcript.
WER does not check whether statements are attributed to the right speaker
WER compares the combined text of a transcript to a reference but does not verify whether statements are attributed to the correct person. If an adviser’s statement is recorded as the client’s, or vice versa, WER will not flag it. The record then shows the wrong person said something important, which can have direct compliance implications.
WER scores from different providers are not always directly comparable
Different providers normalise transcripts in different ways before calculating WER. One tool might strip punctuation and lowercase everything; another might handle numbers differently. A WER of 8% from one vendor and 8% from another may not represent equivalent accuracy. Always check what normalisation approach was used before drawing comparisons
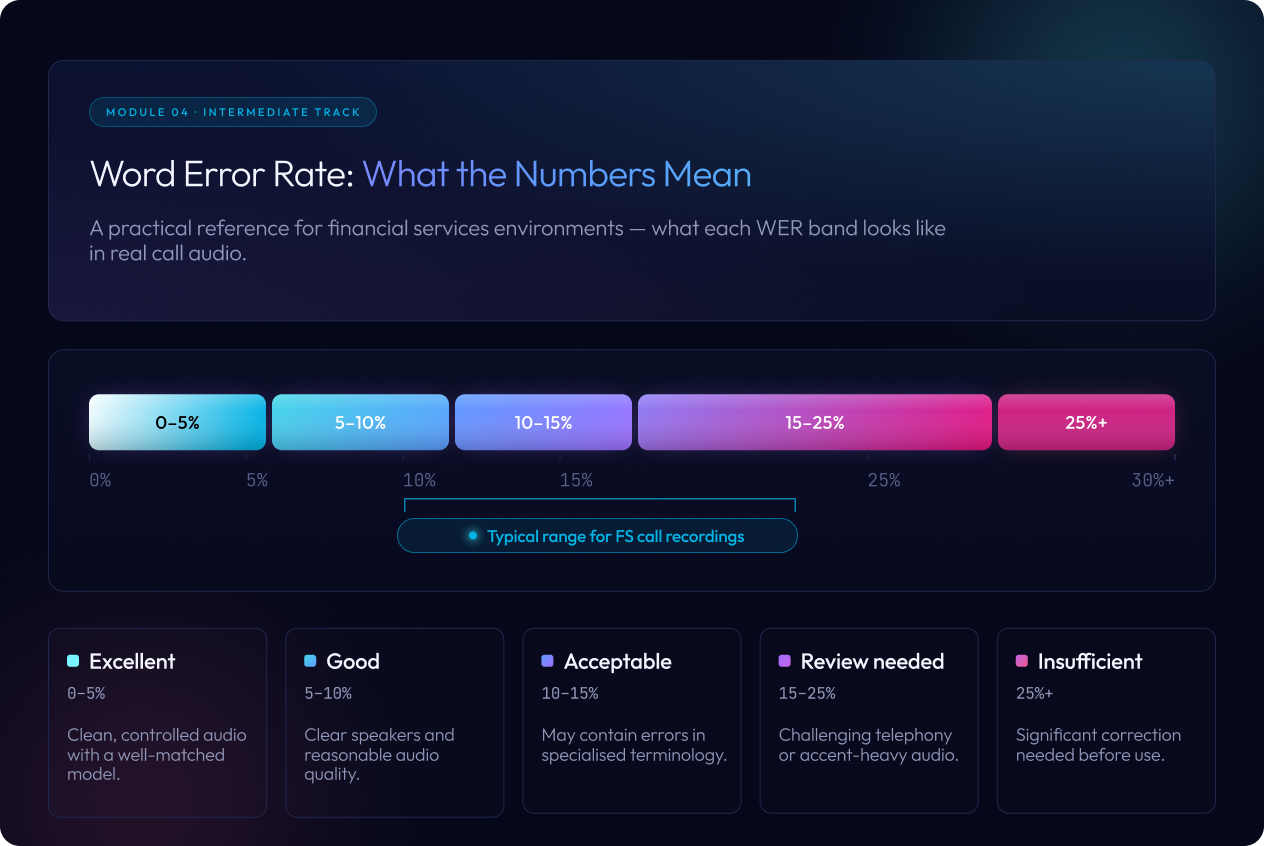
There is no universal benchmark for acceptable Word Error Rate (WER). Performance depends heavily on audio quality, speaker accents, and the vocabulary used in the conversation. The ranges below provide a practical orientation rather than strict thresholds.
- Under 5%: Excellent. Usually seen in clean, controlled audio with close microphones and a well-matched transcription model.
- 5 to 10%: Good. Achievable in commercial environments when speakers are clear and recording quality is reasonable.
- 10 to 15%: Acceptable for some use cases. Transcripts in this range often contain mistakes in specialised terminology, names, or figures.
- 15 to 25%: Requires careful review. Common in telephony recordings, multi-speaker conversations, or audio with strong accents or background noise.
- Above 25%: Generally unreliable for compliance monitoring or record-keeping without significant human correction.
*WER should always be interpreted alongside other checks, such as whether key phrases, figures, and speaker attribution are captured correctly.*
Most financial services calls fall in a more challenging range than vendor figures suggest
Most financial services call recordings fall in the 10 to 20% WER range when processed by general-purpose AI models. This is because calls are typically recorded via telephone at lower audio quality, involve financial terminology the model has rarely encountered, and may include multiple speakers with different accents and speaking styles.
Domain-specific AI models, trained on financial conversations and regulatory language, consistently perform better in this environment. This is covered in detail in Module 5.
Rather than setting a single WER target across all transcripts, the most practical approach is to define “good” based on what the transcript will be used for. Different use cases have different tolerances for error.
For meeting notes and client summaries, key facts must be right
These are often the first place a transcript’s output is read by a human. The priority is accurate capture of names, figures, agreed actions, and key decisions. Minor disfluencies such as “um,” “you know,” and false starts matter less. Missing or incorrect figures and names matter a great deal.
What you need:
- Accurate capture of amounts, dates, product names, and decisions
- Clear identification of who said what
- No significant missing segments
For QA and compliance monitoring, key phrases cannot be wrong or missing
Here the transcript is used to assess whether conduct, process, and regulatory standards were met. Automated compliance monitoring tools read the transcript looking for specific phrases: disclosures, risk warnings, vulnerability cues, complaints. If those phrases are missing or wrong, the monitoring tool draws the wrong conclusion.
What you need:
- High accuracy on key phrases related to disclosures, suitability, and risk
- Reliable speaker attribution so conduct is assessed against the right person
- Strong handling of interruptions and overlapping speech, where regulatory language often gets lost
For evidence and record keeping, the transcript must be traceable and defensible
When a transcript forms part of the evidential record, for example in a complaint investigation or regulatory review, accuracy requirements are at their highest. The document needs to be traceable to the audio and defensible under scrutiny.
What you need:
- A documented, consistent approach to how corrections are made
- Confidence that critical statements were captured as spoken
- The ability to demonstrate how the transcript was produced and reviewed
A simple test to apply across all three use cases
Would a reasonable reviewer reach the same conclusion from the transcript as they would from listening to the full recording? If not, the transcript is not yet fit for that purpose.

Because WER alone does not identify the errors that matter most, financial services teams should build an evaluation approach that goes beyond the headline number.
Check whether critical terms are being transcribed correctly
Build a list of words and phrases that must be accurate for your specific use cases, then review a sample of transcripts specifically against those terms. Categories to include:
- Product and provider names such as ISA, SIPP, specific fund names, and platform names
- Regulatory and process terms used in your firm’s workflows
- Fees, charges, rates, and numerical information
- Client names, addresses, and identifiers
- Key phrases associated with required disclosures or risk warnings
This targeted check regularly surfaces problems that a clean overall WER score conceals.
Check whether statements are attributed to the right speaker
Errors here are most likely when speakers interrupt each other, when one person is speaking more quietly, or when two people are in the same room on a single microphone. Misattribution means conduct is assessed against the wrong person, which is a significant issue for any QA process.
Check for missing or unclear segments, not just incorrect words
Deleted words are not visible in the transcript. You have to infer them from context. A sudden shift in topic, or a section that moves abruptly from “the product involves some level of” to the client asking a question, suggests content has been lost. Missing content is often more consequential than minor wording errors, precisely because there is nothing visible to flag it.
Apply the “same conclusion” test to a sample of transcripts
Read a sample of transcripts without listening to the audio. Then listen to the audio without reading the transcript. Would you reach the same understanding of what was discussed, agreed, and disclosed? If not, the transcript is not meeting its purpose.
Accuracy is not a constant. The same AI model produces different results depending on the audio it receives. Factors that affect accuracy include recording quality and microphone setup, background noise, speaker accents and speaking speed, how many people are speaking at once, and how much similar terminology the model encountered during training.
A single benchmark score does not reflect your full range of calls
A WER score measured in one context may not represent how a system performs across your entire call population. Accuracy should be monitored regularly, particularly when you introduce new advisers, new recording setups, or new product lines, rather than assessed once at deployment and left unchecked.
You have completed Module 4 of the Intermediate Track. You now understand:
- WER measures transcription accuracy by counting substitutions, deletions, and insertions against a reference transcript
- WER is a useful baseline but does not show whether errors change meaning or affect compliance
- Deletion errors, where words are simply missing, can be the most consequential type in regulated conversations
- “Good” accuracy is defined by the use case, not a single universal number
- Financial services transcription evaluation should go beyond WER to check critical terms, speaker attribution, and missing segments
- Accuracy varies with audio conditions and should be monitored on an ongoing basis, not just assessed at setup
What Comes Next
COMING SOON is Module 5: Why Adviser-Client Calls Are Hard to Transcribe. You will learn what conditions cause accuracy to drop, why financial conversations present challenges that general-purpose AI struggles with, and what makes some calls significantly harder to transcribe than others.
